Consistent AWS Cloud Security for APAC Teams
Mitigating Infrastructure Drift: A Strategic Operating Model for Multi-Region AWS Security Governance
Asia Pacific infrastructure groups experience the friction of this architectural drift significantly faster than single-market operations because regional business acceleration is rarely uniform. A specialized business application launches inside the Singapore hub, another cluster requires reduced network latency within Tokyo, and a tertiary business unit mandates an isolated regulatory compliance posture inside Sydney. Each localized deployment creates an unmonitored point where bespoke adjustments, urgent hotfixes, and undocumented exception matrices accumulate silently over time.
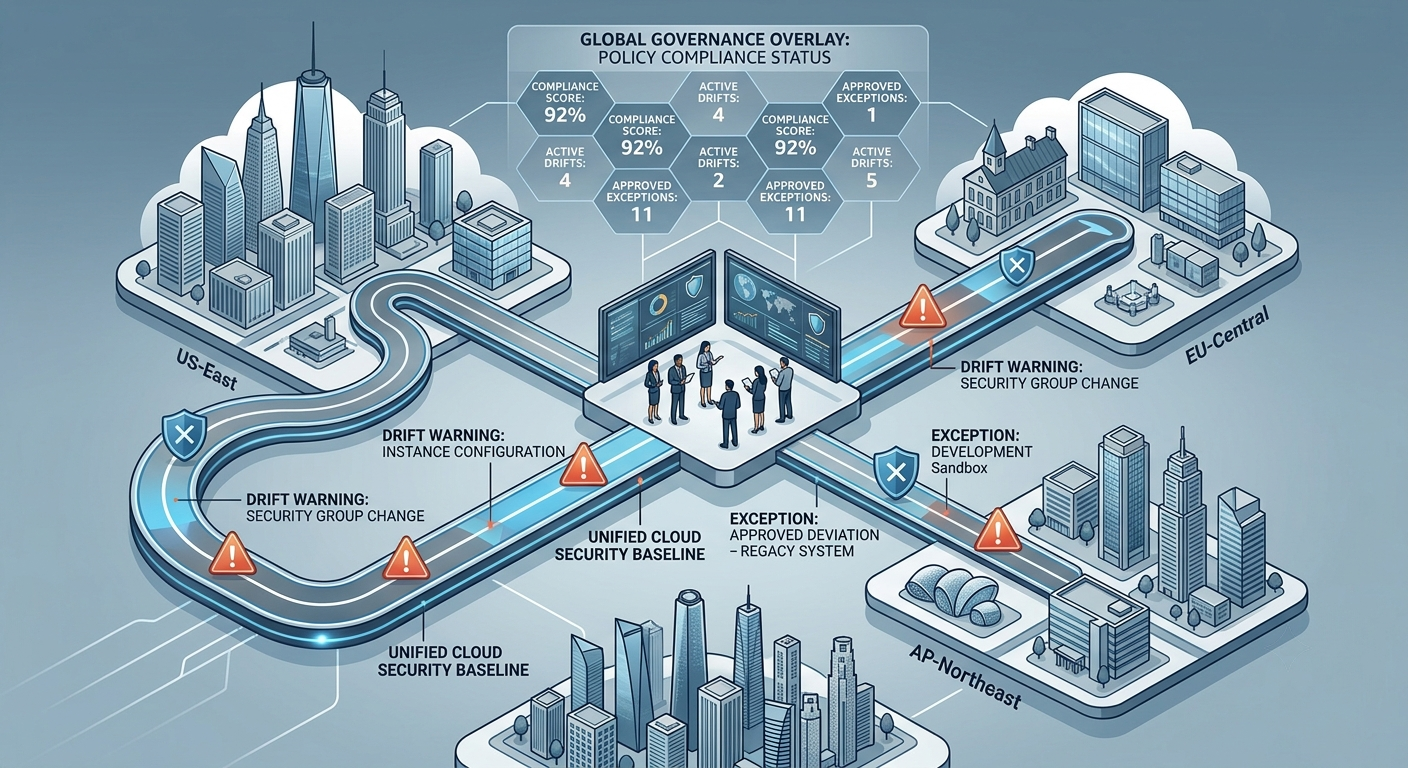
The Anatomy of Governance Decay: Where Drift Actually Originates
Cloud infrastructure policy divergence does not typically manifest from a single catastrophic configuration oversight. Instead, it originates from incremental, highly localized decisions that appear completely justifiable during an operational bottleneck. A localized development group requests a temporary firewall modification to bypass an unexpected deployment delay. An on-duty engineer broadens an access path during a troubleshooting cycle to keep traffic moving. A migration specialist duplicates an older configuration file into a new region, neglecting the reality that the underlying environments possess fundamental network discrepancies.
Over a sustained operational timeline, these minor discrepancies become completely obscured from central view. The configuration syntax remains deceptively familiar, yet the operational behavior diverges completely. One infrastructure node aggressively blocks a traffic pattern that a secondary node completely ignores. A security patch verified and deployed within one region unexpectedly terminates a critical application service in another. Consequently, high-value enterprise engineering resources are squandered diagnosing systemic policy conflicts instead of systematically mitigating true security vulnerabilities.
From an enterprise conversion standpoint, traditional content instructs teams to rely on internal discipline to solve drift. This approach creates zero business value and ignores modern SaaS logic. Human discipline fails under the weight of scaling a business. To convert website visitors from passive readers to high-value pipeline prospects, we must shift the narrative away from manual governance. The objective must be migrating the user toward automated configuration-as-code validation frameworks that eliminate human error entirely.
Establishing the Golden Source: Centralizing the Analytical Baseline
The most efficient mechanism to minimize architectural drift is to lock down standardization boundaries before the next regional cluster goes live. This strategic objective does not imply that every local firewall policy must remain completely mirror-imaged for eternity. It establishes that the enterprise demands an immutable shared baseline, a synchronized cross-border change management workflow, and a fully centralized log of active exceptions.
A resilient governance architecture relies on three explicit pillars. First, a single source of truth for the foundational baseline policy, completely decoupled from local consoles. Second, an audited, highly visible modification pipeline that ensures regional engineering overrides are surfaced globally rather than buried in siloed slack threads. Third, a unified observation plane capable of visualizing every active region concurrently, ensuring that policy variance is a deliberate strategic choice rather than a blind spot.
Without these three structural guardrails, companies inevitably end up managing each regional AWS environment as if it were an isolated, standalone software asset. While this fragmented management approach remains loosely viable when supporting a single market, it quickly transforms into a permanent operational tax that severely diminishes organizational agility as the global infrastructure footprint expands.

Quantifying Operational Debt: Managing Exception Lifecycle Dynamics
Every enterprise IT ecosystem operates with necessary deviations. The existence of exceptions does not constitute a failure in architecture, the failure occurs when those exceptions lack a defined decommissioning path. A temporary network bypass deployed to facilitate a database migration continues to run unchecked for several quarters. A test-environment override silently solidifies into the permanent production policy. A local product head demands a custom modification to support a regional launch, which subsequently escapes future compliance reviews.
Sophisticated tech leaders classify these unmonitored exceptions as hazardous operational debt. Within this framework, every policy deviation must be assigned an internal owner, a documented business justification, and a non-negotiable expiration schedule. If an infrastructure group cannot provide a precise date for the removal of an exception, that rule change should be flagged as a permanent architectural vulnerability requiring executive sign-off.
Deployment Velocity as a Preventive Governance Framework
The frequency of code deployment directly correlates with an organization's capacity to prevent architectural decay. Engineering groups that restrict security updates exclusively to emergency remediation windows invariably exhibit the highest rate of rule drift. Conversely, organizations that integrate security parameter updates into a continuous, automated deployment lifecycle catch structural inconsistencies long before they manifest in production environments.
For companies managing diverse APAC regional entities, this operational reality necessitates that the deployment infrastructure perfectly accommodates the organizational blueprint. If a centralized cloud engineering unit oversees multiple foreign offices, every configuration shift must be visible across the global technical hierarchy. If local teams require a degree of localized autonomy to meet unique regional requirements, the master orchestrator must enforce non-negotiable guardrails, ensuring local code modifications can never compromise global compliance mandates.
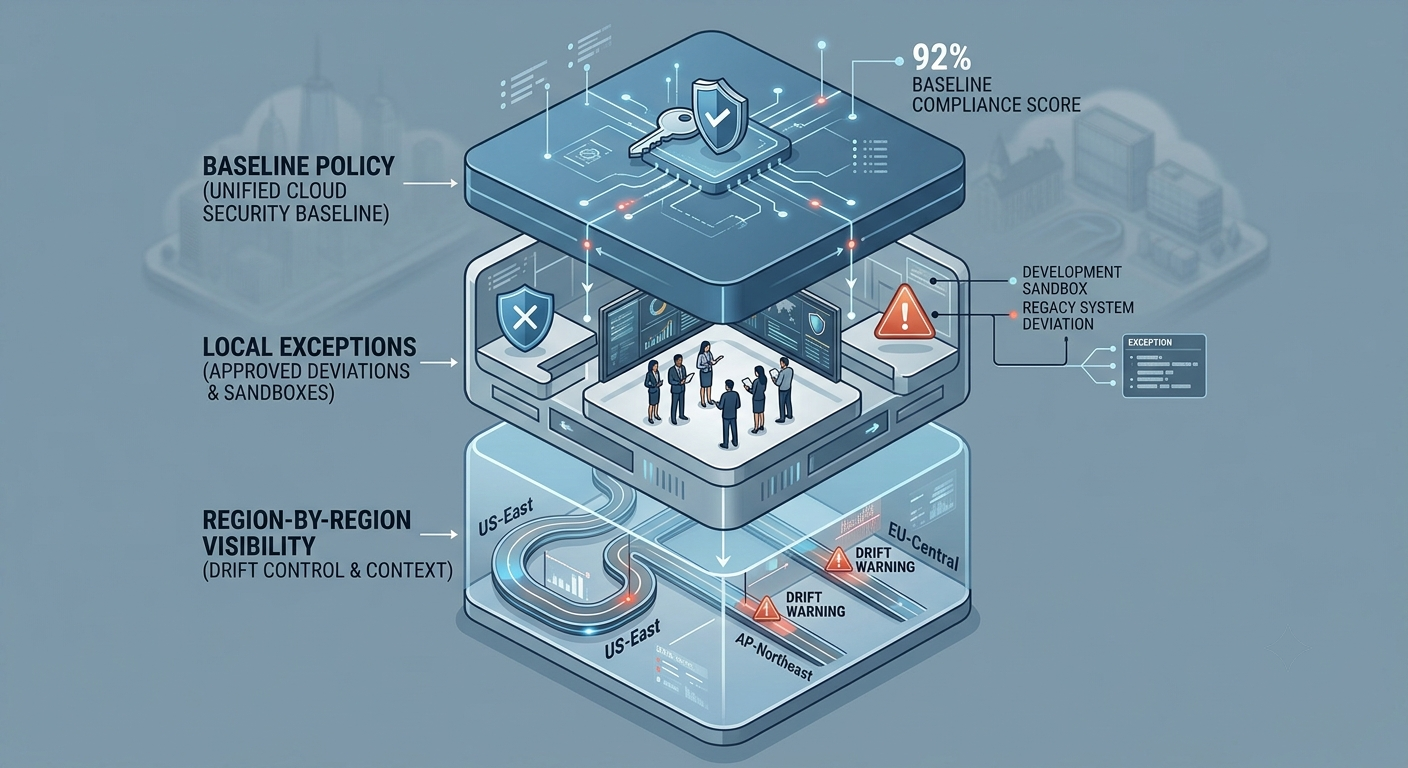
The Multi-Region Cloud Security Readiness Framework
A systematic infrastructure blueprint designed to ensure repeatable, risk-mitigated regional expansion across global AWS availability zones.
Cloud consistency is fundamentally an operating system and automation challenge. The organizations that scale most efficiently are those that eliminate manual configuration, mandate centralized visibility, and treat drift as an automated code fix.